
How to Detect Changes Between Model Versions
When releasing a new model version, Mona allows you to get a more granular understanding of your new model's performance compared to your previous model(s) and can alert you on specific segments in your data where your model underperforms.
Instead of relying only on the model's average scores compared to the previous version(s), Mona dives deeper into your data to give you specific segments where your model underperforms, either on test data, inference time data, or both.
This can easily be achieved with Mona's verse - AverageDriftAcrossVersions.
{
"stanzas": {
"stanza_name": {
"verses": [
{
"type": "AverageDriftAcrossVersions",
"segment_by": [
"stage",
"state"
],
"metrics": [
"risk_score",
"approved_amount"
],
"min_segment_size_fraction": 0.05,
"min_anomaly_level": 0.4,
"version_field": "model_version",
"num_versions_benchmark": 2,
"order_versions_by": "LATEST_TO_RECEIVE_DATA"
}
]
}
}
}This verse can also be set via the configuration graphic interface in the configurations page.
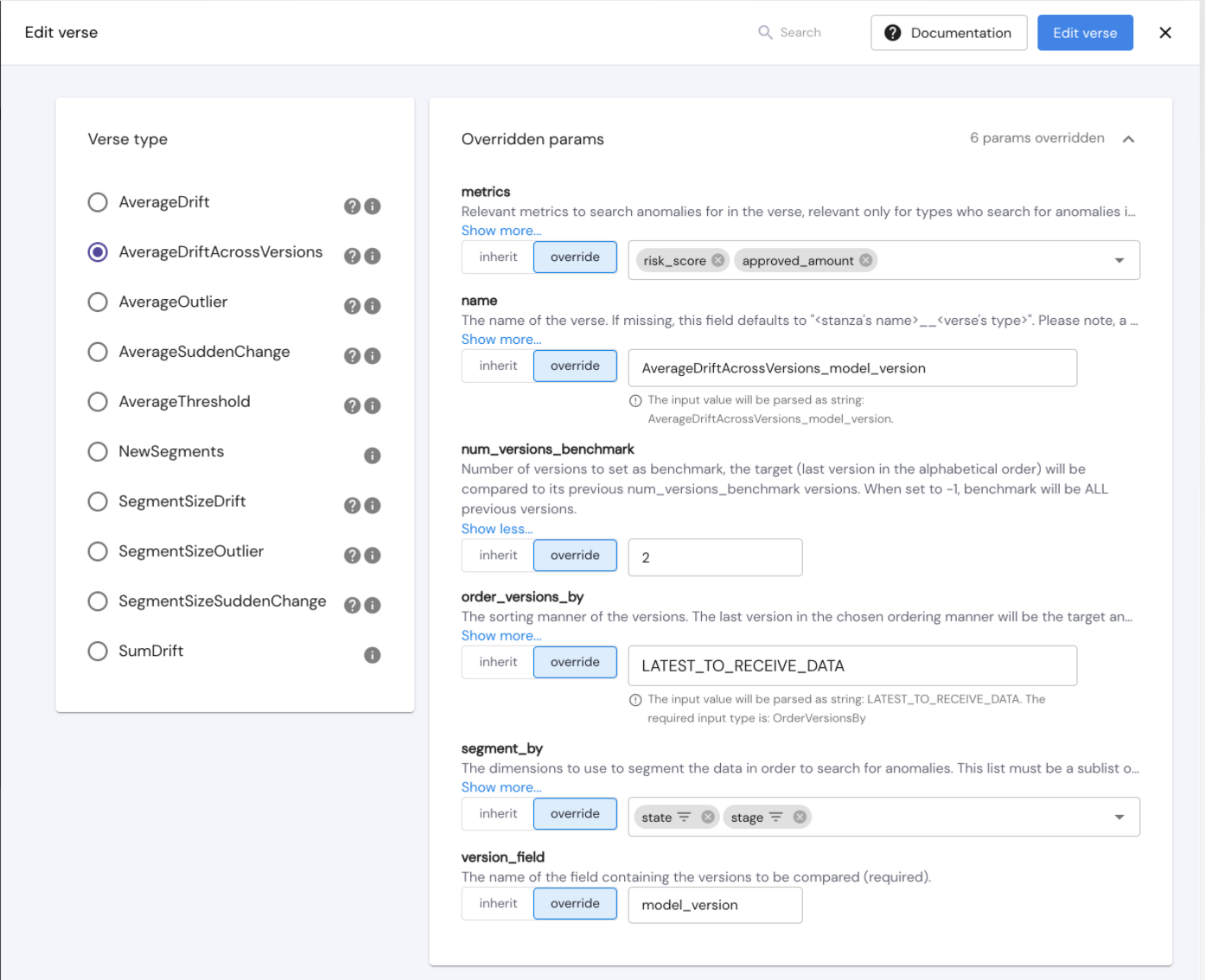
This verse is easily configured and does not require you to specify the specific version names.
Using the “version_field” param you will define the field which states the version and then the “order_versions_by” param will determine the order of versions and consequently the latest version, and the “num_versions_benchmark” param will determine the number of previous versions to check against.
In the above example, we see an AverageDriftAcrossVersions verse which is configured to search for statistically significant changes in the average of "risk_score" and "failed_classification" in any specific "stage" or "state" (or any intersection of stage and state), between the latest model version and the 2 versions prior to that. The latest model version is the latest version to receive data.
We use "min_anomaly_level" to define that a drift occurs when the change in averages between the benchmark and target sets normalized by the standard deviation (of the metric value distribution in both benchmark and target sets) is larger than 0.4.
The "min_segment_size_fraction" param will filter out segments that are smaller than 5% of the data.
This is an example insight that can be generated by this verse:

This insight shows you a descending drift in the average of risk_score when looking at "stage": "test" and "state": "Arizona" where the benchmark baseline is "model_version": "v1" and the target baseline is "model_version": "v1".
Updated 3 months ago